GATE annotation model
About
To help build the educe package, I’m doing a small survey of annotation models used by tools I know about. I’ve done a model for Glozz so far as it’s what we’re using as annotation tool. But the work I’m doing involves trying to work with annotations from third party tools, for example, part of speech taggers and to do this work properly, I’d like to make sure I’m asking the right questions about integrating such heterogeneous annotations. Yes, standoff annotation may well be the answer, but what exactly do we have in mind?
If you’re working with natural language processing pipelines, you’re likely familiar with at least one of GATE or UIMA. Both frameworks provide a model, an API, and a fancy helper GUI that allow you to assemble pipelines of arbitrary NLP components. Generality is the name of the game, the idea in both frameworks being that you should be able to suck into them and any new tools that come along, and also to mix and match them at will. There also seems to be a fair amount of interoperability between the two frameworks, the two teams having cooperated to make it so that UIMA can run GATE components and vice-versa.
Since GATE appears to be the simpler (at least older) of the two frameworks, I’ll start by examining this one in a bit more detail. GATE was originally based on the TIPSTER architecture (Grisham 97), but its core model was slightly revised in version 2 (one span per annotation, annotations as graphs). It’s this later version of the model that I’ll describe below. Note that I’ll be using Haskell as a sketching tool as usual, but it should be possible to ignore it outright.
Features and feature maps
At the heart of GATE annotations is notion of a feature map. Features in GATE are attribute-value pairs, with strings for the attributes, and arbitrary Java objects for values. GATE provides a map/dictionary interface to feature maps, so we can assume keys to be unique (as would be standard).
1 2 3 4 | |
Feature maps appear in at least three places, as data associated with:
- individual annotations
- documents as a whole
- corpus of documents
Annotation DAGs
Building up from the notion of a feature is that of an annotation. The GATE document describe the annotations on a document as forming a directed acyclic graph. The nodes of the graph would be offsets into the document (between characters), and the edges would be annotations of all sorts, each annotation being labelled by an identifier, a type (eg. token, sentence), and a feature map adding additional information.
5 6 7 8 9 10 11 12 13 14 15 16 17 18 | |
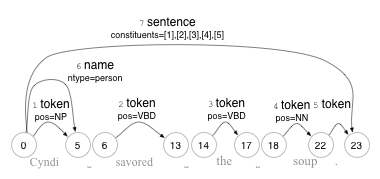
For illustration, the graph below shows what the annotation DAG for the sentence “Cyndi savored the soup.” might look like. Note that the text of the sentence is not properly speaking part of the graph (standoff annotation), but are presented on the diagram, but are provided as a visual hint.
Documents and corpora
Now that we have a representation of features and annotations, the rest of the GATE model is a matter of packaging: a document associate text with annotations and metadata (eg. author), and a corpus is a set of documents plus additional metadata (eg. institution that harvested the corpus).
Looking a bit closer into the documents, it’s worth noting how annotations are not necessarily all lumped together but grouped into multiple annotation sets. I’m not sure what the implications of these is from a modelling standpoint, but it would make sense if we want to explicitly model the fact that annotations come from different sources. For example, you might associate each annotation set with metadata like the tool or annotator that produced it, or its annotation schema.
20 21 22 23 24 25 26 27 28 29 30 31 32 33 | |
Summary
Taking a very broad view of the GATE model as I understand it, we can say that it makes the following implicit choices:
- substrate : text/characters
- typology : annotations on text (like Glozz units)
- spans : contiguous, one per annotation
- features : attribute-value dictionary; rich values
Drilling down a little bit, we can understand the model as having four layers:
- corpus: set of documents, features
- document: text, (set of) set of annotations, features
- annotation: type, span, features
- features: rich attribute-value pairs
Notes and comments
It’s worth noting the use of arbitrary value types on features (not necessarily atomic). I’d be curious to see what sorts of values GATE features tend to take in practice. So far, I’ve seen strings and lists of strings, but I wonder if it ever gets more sophisticated than that. Do you have trees? Maybe some sort of recursive feature structure scheme?
Also, there is as far as I can tell no explicit notion of annotations on other annotations; however, perhaps the possibility of encoding one in the rich feature structures? The GATE docs provide the example of using a constituents feature in which the annotation that corresponds to some parent node in a tree could point at the annotations for its daughters. Maybe using pointers in feature maps is good enough for our needs? (Also the notion of a text span may not be so useful on such annotations, but could maybe be worked around with a nonsense span, or by computing one from the leaves)
Finally the GATE docs seem to say that their model is “largely compatible” (what does the largely mean? where is it not compatible) with the Bird and Liberman 1999 annograph stuff, which I hope to look into somewhere along the line.